In deze datablogs voor Hack de Valse Start lichten wij steeds een dataset uit ter voorbereiding op de hackathon. Wij trappen af met het onderwerp: passend voortgezet onderwijs in Amsterdam. Deze datablog kan een eerste aanzet zijn tot het onderzoeken van bestedingen in het passend (en speciaal) voortgezet onderwijs. Hiervoor combineren wij verschillende datasets, wat voor nieuwe inzichten kan zorgen in de relatie tussen omgevingsfactoren en passend onderwijs.
Context

De laatste jaren hebben er veel veranderingen in het (speciaal) onderwijs plaatsgevonden. Met name op het gebied van taakverdeling voor leerlingen die speciale zorg nodig hebben. Voor 2014 kregen ouders de mogelijkheid om leerlinggebonden financiering, ook wel het rugzakje genoemd, aan te vragen bij extra zorgbehoeftes van een kind.
Sinds 2014 wordt Passend Onderwijs, dat georganiseerd wordt in samenwerkingsverbanden, toegepast. Een samenwerkingsverband, waar vrijwel alle scholen deel van uitmaken, maakt een ondersteuningsplan voor de regio waarin staat hoe Passend Onderwijs wordt gerealiseerd.
Het aantal rugzakjes in een bepaald gebied geeft analytische mogelijkheden, bijvoorbeeld om te kijken of er een verband is tussen het aantal rugzakjes in een gebied en de sociaaleconomische status in een gebied. De onderliggende gedachte is hierbij dat de sociaaleconomische status van ouders invloed heeft op de aanvraag van rugzakjes.
Vraag: heeft het aantal rugzakken in een 4-cijferig postcodegebied te maken met de sociaaleconomische status van dat gebied?
De data
1. Open data: kengetallen leerlingen voortgezet onderwijs Amsterdam
In deze dataset is veel te vinden over de bekostiging van Passend Onderwijs, maar ook over de aanspraak op rugzakken per vestiging gemeten in 2012. Wij hebben de volgende informatie per vestiging nodig:
– Vestigingsnaam
– Postcode
– Aantal leerlingen
– Aantal rugzakken
Toelichting: het aantal leerlingen met een rugzak dat naar school gaat op één van de scholen in het samenwerkingsverband Amsterdam. Het percentage rugzakken wordt berekend door (aantal rugzakken)/(aantal leerlingen)*100.
2. Open data: sociaal-economische status per 4-cijferig postcodegebied
De sociaal-economische status van een wijk is afgeleid van een aantal kenmerken: het gemiddelde inkomen in een wijk, het percentage mensen met een laag inkomen, het percentage laag opgeleiden en het percentage mensen dat niet werkt. Wij hebben de volgende informatie nodig per 4-cijferig postcodegebied:
– Postcode
– Statusscore 2010
– Statusscore 2014
Toelichting: een statusscore is een getal dat de status van een wijk weergeeft. Hoe hoger de score, hoe hoger de status van de wijk is. Een lage score duidt op een lage status. Wij maken gebruik van een middeling tussen de statusscore van 2010 en 2014, omdat wij geïnteresseerd zijn in de statusscore van 2012.
Voorbeeld analyse
Om dit voorbeeld te maken hebben we de 4-cijferige postcode, het percentage leerlingen met een rugzakje en de geschatte statusscore in 2012 gebruikt. Dat levert een lijst op met 47 postcodes in Amsterdam. Zie het .csv bestand hier. Als je het .cvs bestand inlaadt in een statistisch software analyse programma, kun je verder analyses uitvoeren. In dit voorbeeld gebruiken we RStudio voor de analyse en visualisatie. Wil je de gehele analyse ook uitvoeren, zie de dan de syntax hier.
Ten eerste controleren we visueel op de relatie tussen het percentage rugzakken in een postcodegebied en de statusscore van dat postcodegebied. Hiervoor gebruiken we de default correlatie analyse Pearson’s r. Dat levert het volgende plaatje op:
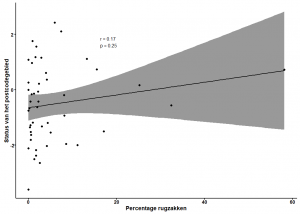
We kunnen hieruit verschillende zaken aflezen, zo lijkt er slechts een zwakke, bovendien niet significante, relatie te zijn tussen het percentage rugzakken en de statusscore (Pearson’s r = 0.17; p = 0.25). We zien echter ook dat het grootste deel van de postcodegebieden slechts 10% of minder rugzakken heeft. Daarom vermoeden we dat de relatie eventueel te verduidelijken is door de extreme observaties in rugzakken niet mee te nemen in de analyse. We behandelen voor nu alle observaties van rugzakken boven de 10% als extremen die de resultaten kunnen vertekenen. Als wij de analyse opnieuw doen dan genereert dat het volgende plaatje:
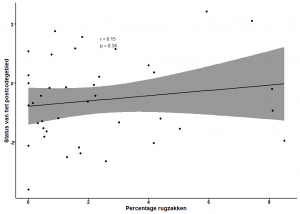
De nieuwe visualisatie levert echter geen sterkere of significante relatie op (Pearson’s r = 0.15; p = 0.34). Wellicht helpt het als we afstappen van de assumptie van een normaal-verdeling in de data. Hiervoor moeten we een andere correlatie analyse gebruiken.
Ten tweede controleren we dus op twee andere correlatie analyse methoden: Kendall’s Tau en Spearman’s rho. Een snelle analyse laat zien dat beiden dezelfde uitslag geven als de Pearson analyse (tau 0.076379, p-value = 0.491; rho 0.1155745, p-value = 0.4776).
Gebaseerd op deze specifieke analyse kunnen we dus niets zeggen over de exacte relatie tussen het percentage rugzakken en de statusscore van een postcodegebied, waardoor onze vraag onbeantwoord blijft. We hebben echter wel kunnen vaststellen dat er geen directe correlatie is tussen beiden variabelen. Dit lijkt ons vermoeden van de negatieve effecten van de omgeving (gemeten in een lage statusscore) op het aantal rugzakken (dat zou dan hoger moeten zijn) te ontkrachten. Wellicht dat met de juiste transformaties wel een verband aangetoond kan worden. Kun jij hier meer over zeggen?
Vervolg vragen:
– Welke resultaten krijgen wij als we sociaal-economische status opsplitsen naar bijvoorbeeld opleidingsniveau en inkomen, en vervolgens dezelfde analyse uitvoeren? Wellicht is deze dataset handig.
– Kan er eenzelfde soort analyse gemaakt worden voor het primair onderwijs? Zijn vergelijkingen tussen primair en voortgezet onderwijs mogelijk? Wellicht is deze toolbox handig.
– Hoeveel wordt er besteed aan passend onderwijs?
– Welke buurtkenmerken zijn belangrijk bij het signaleren van bestedingen in het passend onderwijs budget?
– Kunnen wij iets zeggen over passend onderwijs en speciaal onderwijs in relatie tot stigmatisering?
Denk ook aan:
– Is het mogelijk om de passen onderwijs en de bestedingen hieraan te volgen over tijd?
– Wat voor gevolgen hebben aanpassingen in wet- en regelgeving op de bestedingen?
– Wat betekent de verschuiving van speciaal onderwijs naar passend onderwijs voor andere domeinen, zoals de schoolkwaliteit?
– Hoe kunnen we de informatie in de data visueel maken?
Hack jij de Valse Start?
Op 3 maart 2018 vindt Hack de Valse Start plaats. Tijdens deze hackathon gaan we met open onderwijs data aan de slag om kansenongelijkheid in het onderwijs beter te kunnen signaleren en eventueel aan te pakken. Doe je mee? Aanmelden kan hier.
Bronnen:
– Informatie passend onderwijs, inclusief aantal rugzakken per vestiging: https://www.passendonderwijs.nl/kengetallen-2012/
– Voor Amsterdam specifiek: https://passendonderwijs.nl/wp-content/uploads/2013/04/VO2708-Amsterdam-en-Diemen1.xls
– Informatie over sociaaleconomische status op 4-cijferig postcode niveau: http://www.scp.nl/Formulieren/Statusscores_opvragen
– Bredere data voor alle samenwerkingsverbanden is te vinden of op te vragen via: https://swv.passendonderwijs.nl/
Hack jij de Valse Start?
Op 3 maart 2018 vindt Hack de Valse Start plaats. Tijdens deze hackathon gaan we met open onderwijs data aan de slag om kansenongelijkheid in het onderwijs beter te kunnen signaleren en eventueel aan te pakken. Doe je mee?
Icons: Freepik from www.flaticon.com